

Me gustan las metodologías. Aunque no te aseguran el éxito, te guían por el camino que debes transitar para ejecutar un proyecto con mayor probabilidad de éxito.
En el ámbito de la minería de datos, la metodología CRISP-DM (Cross Industry Standard Process for Data Mining) se ha convertido en un estándar de factor del mercado. Surgida en dos empresas que han sido pioneras en la aplicación de minería de datos a los procesos de negocio: DaimlerChrysler y SPSS.
La metodología CRISP-DM establece un proyecto de minería de datos como una secuencia de fases:
- Comprensión del negocio.
- Compresión de los datos.
- Preparación de los datos.
- Modelado.
- Evaluación.
- Despliegue.
En este post vamos a revisar las fases en la que se estructura un proyecto de minería de datos en salud tomando como referencia CRISP-DM.
Comprensión del negocio.
El objetivo de esta fase es alinear los objetivos del proyecto de data mining con los objetivos del negocio. Tratando así de evitar embarcarnos en un proyecto de minería de datos que no produzca ningún efecto real en la organización.
En esta fase deberemos ser capaces de:
- Establecer los objetivos de negocio.
- Evaluar la situación actual.
- Fijar los objetivos a nivel de minería de datos.
- Obtener un plan de proyecto.
Como ejemplo ilustrativo de la metodología vamos a considerar el caso de una organización hospitalaria especializada en oncología que pretende mejorar la precisión en el diagnóstico de células cancerígenas que lleva a cabo el laboratorio de anatomía patológica.
Para ello se procederá a realizar una captura digital de una imagen de un aspirado con aguja fina de una masa mamaria y se medirá de forma automatizada una serie de atributos sobre la imagen que nos permita clasificar el tejido analizado como maligno o benigno.
El objetivo final es establecer un sistema automatizado que permita clasificar automáticamente una citología del paciente y complemente la labor de diagnóstico del patólogo, mejorando la precisión diagnóstica.
Una vez establecidos y alineados los objetivos se creará un plan de proyecto que incluya las fases, tareas y actividades necesarias para conseguir los objetivos.
Comprensión de los datos.
Dos puntos clave en esta fase: conocer los datos, estructura y distribución, y la calidad de los mismos.
En esta fase deberemos ser capaces de:
- Ejecutar procesos de captura de datos.
- Proporcionar una descripción del juego de datos.
- Realizar tareas de exploración de datos.
- Gestionar la calidad de los datos, identificando problemas y proporcionando soluciones.
El proyecto se basará en el Breast Cancer Winscosin Data Set. Está formado por un conjunto de 569 observaciones con 30 variables de tipo real. El conjunto de datos no presenta valores nulos.
Las variables se calculan a partir de una imagen digitalizada de un aspirado con aguja fina (FNA) de una masa mamaria. Describen las características de los núcleos celulares presentes en la imagen.
Las variables son las siguientes:
- Radio
- Textura
- Perímetro
- Área
- Suavidad
- Compacidad
- Concavidad
- Puntos cóncavos
- Simetría
- Dimensión fractal
El conjunto de datos está formado por la media, el error estándar y el peor de los valores de las variables para cada una de las imágenes.
El conjunto de datos está formado por 212 observaciones clasificadas como malignas y 357 observaciones clasificadas como benignas.
Se procede a realizar un análisis estadístico básico. A continuación se muestra el cálculo de la media, la desviación estándar y los cuartiles para las primeras nueve variables numéricas.
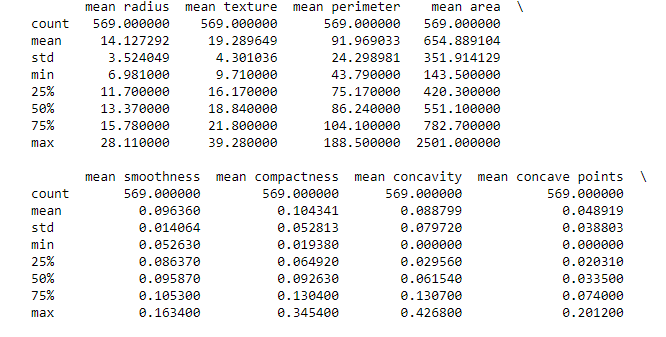
Los datos no presentan problemas de calidad.
Preparación de los datos
El objetivo final de esta fase es obtener los datos finales sobre los que aplicarán los modelos.
En esta fase deberemos ser capaces de:
- Establecer el universo de datos con los que trabajar.
- Realizar tareas de limpieza de datos.
- Construir un juego de datos apto para ser usado en modelos de minería de datos.
- Integrar datos de fuentes heterogéneas si es necesario.
Como ejemplo de exploración visual de los datos dibujaremos un histograma para alguno de los atributos del dataset. La finalidad es observar cómo se distribuye cada uno de los atributos en función del valor de clase que toman, para poder identificar de forma visual y rápida si algunos atributos permiten diferenciar de forma clara los diferentes diagnósticos de los tumores.
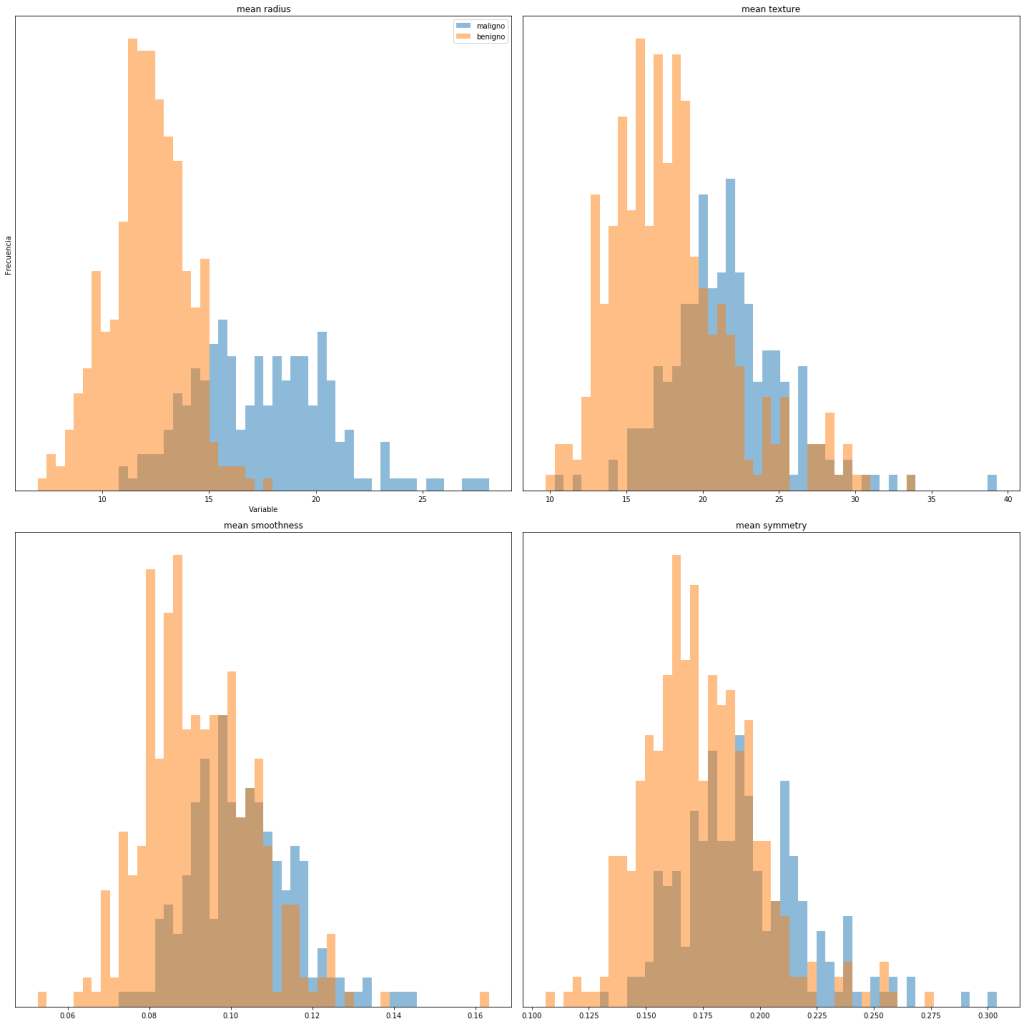
Los histogramas sugieren que el atributo mean radius permite diferenciar la presencia de células tumorales o no en la imagen.
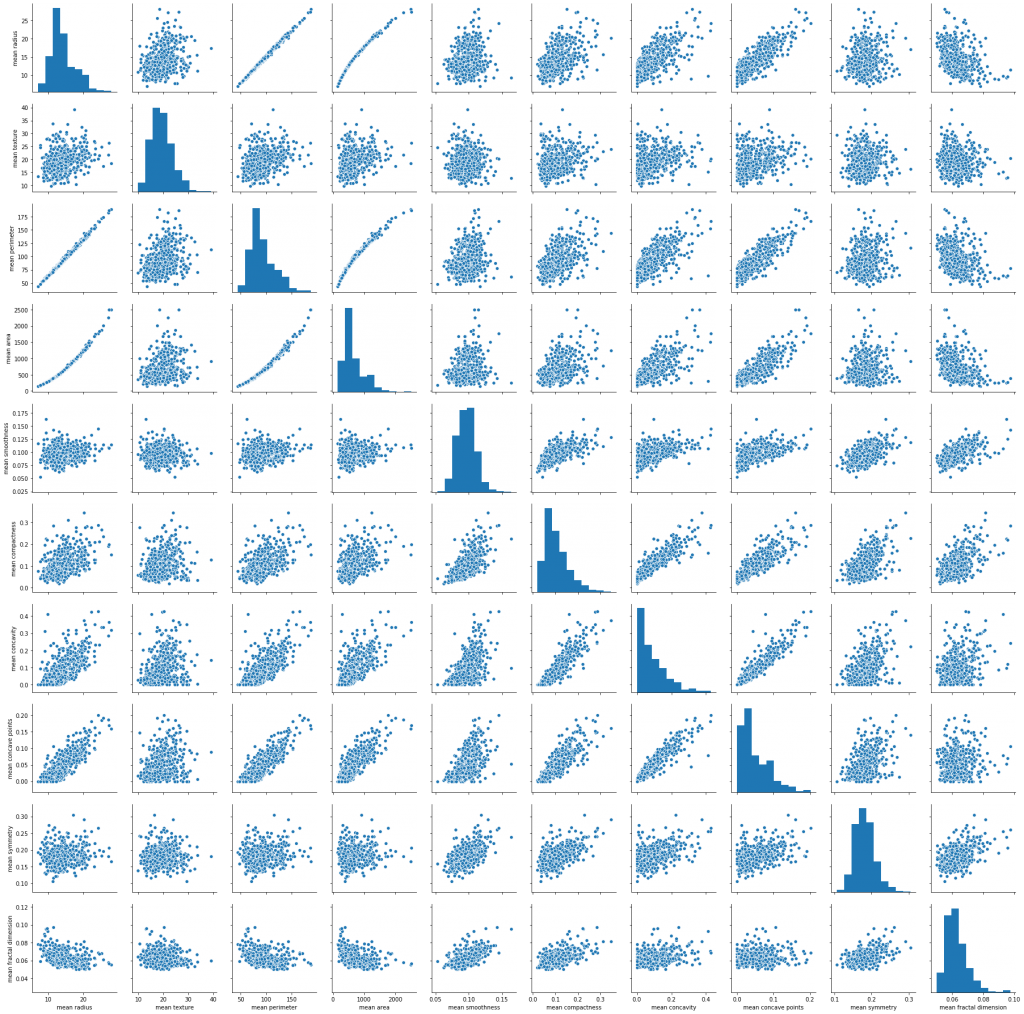
Otro análisis relevante que nos permitiría descartar atributos redundantes para la construcción del modelo sería la matriz de correlación. Por ejemplo, el gráfico siguiente muestra la elevada y esperada correlación que existe entre el radio, el área y el perímetro.
Otra técnica también muy utilizada en esta fase es la de reducción de la dimensionalidad. Para ello podríamos usar análisis de componente principales (PCA). Se trata de una transformación de datos a un espacio de dimensión menor pero manteniendo la mayor parte de la información del dataset original. Si consideramos un espacio de dimensión 2 formado por las dos primeras componentes principales se obtiene la siguiente distribución para cada de las clases objetivo:
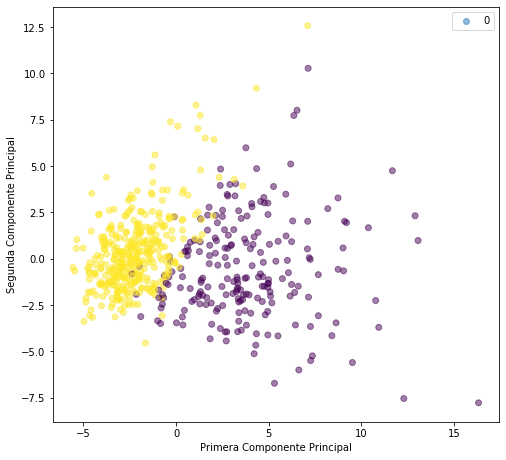
La finalidad es observar cómo se distribuye cada uno de los atributos en función del valor de clase que toman, para poder identificar de forma visual y rápida si algunos atributos permiten diferenciar de forma clara los diferentes diagnósticos de los tumores.
Modelado
El objetivo último de esta fase es construir un modelo que nos permita alcanzar los objetivos del proyecto.
En esta fase deberemos ser capaces de:
- Seleccionar las técnicas de modelado más adecuadas para nuestro juego de datos y nuestros objetivos.
- Fijar una estrategia de verificación de la calidad del modelo.
- Construir un modelo a partir de la aplicación de las técnicas seleccionadas sobre el juego de datos.
- Ajustar el modelo evaluando su fiabilidad y su impacto en los objetivos anteriormente establecidos.
Nos encontramos ante un problema de clasificación. Aplicaremos un método de aprendizaje supervisado, concretamente el clasificador RandomForest, para predecir el diagnóstico de cáncer de mama (tumor benigno o maligno), usando el conjunto de datos original con todos los atributos.
Dividimos las observaciones en un conjunto de entrenamiento para construir el modelo y otro conjunto de test para evaluarlo. Para ello, a partir de dataset inicial tomaremos el 75% de las observaciones junto con su etiqueta de clase asociada para el conjunto de entrenamiento. El 25% restante se asignan al conjunto de test.
La implementación la realizaremos en Python, utilizando la librería sckit-learn.
Evaluación del modelo
En esta fase nos centrarnos en evaluar el grado de acercamiento del modelo a los objetivos de negocio.
En esta fase deberemos ser capaces de:
- Evaluar el modelo o modelos generados hasta el momento.
- Revisar todo el proceso de minería de datos que nos ha llevado hasta este punto.
- Establecer los siguientes pasos a tomar, tanto si se trata de repetir fases anteriores como si se trata de abrir nuevas líneas de investigación.
Siguiendo nuestro ejemplo, para la evaluación del modelo calcularemos una serie de métricas sobre un conjunto de datos (conjunto de test) que el modelo no conoce. Métricas habituales son la precisión (accuracy), sensibilidad y F-score:
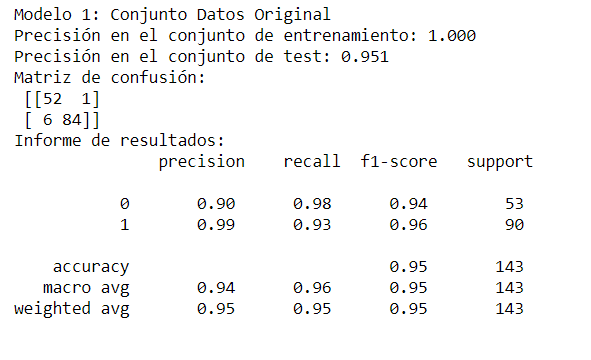
Observamos que la precisión de nuestro modelo sobre el conjunto de test es del 95%, lo que indica que es capaz de clasificar correctamente el 95% de las muestras nuevas analizadas.
Si la precisión alcanzada por nuestro modelo no fuese la adecuada para satisfacer los objetivos del proyecto entraríamos en un proceso iterativo con el objetivo de conseguir un modelo mejor. Esto podría implicar:
- Tunning de los hiperparámetros del modelo.
- Seleccionar otra técnica de construcción de modelos: SVM, redes neuronales, etc…
Despliegue
El objetivo último de esta fase es realizar el despliegue de los resultados obtenidos de forma que sea propagado a los usuarios finales así como el mantenimiento del mismo una vez el despliegue haya finalizado.
En esta fase deberemos ser capaces de:
- Diseñar un plan de despliegue de modelos y conocimiento sobre nuestra organización.
- Realizar seguimiento y mantenimiento de la parte más operativa del despliegue.
- Revisar el proyecto en su globalidad con el objetivo de identificar lecciones aprendidas.
Siguiendo con nuestro ejemplo el despliegue de la solución implicaría tareas como:
- Implantación de un sistema de captura digital de la imagen de anatomía patológica.
- Implantación de software de clasificación automática de tejidos de cáncer de mama.
- Integración con el software del laboratorio de anatomía patológica.
- Implantación de nuevos procedimientos operativos del laboratorio de anatomía patológica.
- Monitorización del funcionamiento del nuevo sistema y grado de adherencia de los usuarios al mismo.
- Medición del grado de precisión diagnóstica y la eficiencia del laboratorio tras la puesta en marcha del sistema.
Espero que te haya resultado ilustrativo este post sobre metodologías de de análisis y minería de datos en salud. Esta metodología es la que usamos en nuestra solución Conectando Datos, por lo que si tienes algún tipo de necesidad en este sentido no dudes en contactar conmigo.