

Los algoritmos de clustering se utilizan para agrupar elementos que son similares entre sí. Vamos a explorar si sería interesante utilizar algoritmos de clustering para agrupar pacientes.
Utilizaremos un dataset con datos de pacientes anonimizados proveniente del V.A. Medical Center in Long Beach, CA. El objetivo es encontrar grupos de pacientes similares dentro del conjunto de pacientes que han sufrido de enfermedad cardiovascular. Esto daría lugar a la posibilidad de utilizar terapias específicas para cada grupo de pacientes y poder analizar sus resultados.
En este post vamos a realizar, con un objetivo didáctico, un análisis para estudiar si existe un modelo que nos permita separar en grupos homogéneos los pacientes que han sufrido de enfermedad cardiovascular. Aunque se trate de un ejercicio didáctico, se ilustrarán las etapas típicas de un proyecto de minería de datos y veremos que nos permite extraer conclusiones interesantes.
Seguiremos de una forma muy resumida las etapas que se describen en nuestra guía Etapas de un Proyecto de Minería Datos.
Definición de la tarea de data mining
En este punto se trata de establecer cuál es el objetivo del proyecto de data mining. Nuestro objetivo es segmentar el conjunto de pacientes con enfermedad cardiovascular en grupos lo más homogéneos posibles de forma que podamos considerar una terapia específica para cada grupo de pacientes con enfermedad cardiovascular. Para ello vamos utilizar un modelo de clustering y el método de los centroides k-means.
Para el análisis se considera cada paciente (cada observación) como un punto en un espacio geométrico n-dimensional (n es igual al número de variables). El método k-means parte de un número de grupos prefijado y mediante una selección aleatoria inicial de los centros, se itera de la siguiente forma:
Hasta encontrar una distribución estable de los grupos:
- calculo la distancia de cada paciente a los distintos centros
- asigno el paciente al centro más cercano
- vuelvo a calcular los centros
Origen de los datos
Lo ideal sería extraer los datos del data warehouse de tu organización. Pero como la tecnología aún no está lo suficientemente extendida en nuestros hospitales lo más probable es que extraigas la información del sistema de historia clínica electrónica (EHR) que haya implantado en tu centro.
Nosotros vamos a utilizar el Cleveland Dataset de enfermedades cardiovasculares que puedes descargar de la plataforma Kaggle.
El Cleveland Dataset está formado por 13 variables tal como se describe en la siguiente imagen:

Seleccionaremos sólo aquellos casos que corresponden a pacientes con enfermedad cardiovascular (Class con valores distintos de 0).
Preparación de los datos
Una vez que disponemos de los datos hay que prepararlos para que podamos aplicar el método de construcción de modelo que hemos elegido. Esta fase aunque parezca sencilla, junto con la anterior, consume el 70% del tiempo de un proyecto de minería de datos.
Las técnicas habituales son: limpieza de datos, transformación de datos y reducción de la dimensionalidad.
En primer lugar, cargaremos el dataset, le echamos un vistazo y verificamos que todos los datos son numéricos. Este punto es muy importante pues los algoritmos de clustering necesitan de datos de tipo numérico para poder ejecutarse.

A continuación procederemos a realizar una exploración visual de los datos para familiarizarnos con los datos antes del clustering.
También consideramos si es necesario algún escalado de los datos. Los algoritmos de clustering son muy sensibles a la escala de las variables. Si tuviesen escalas diferentes, las variables de mayor magnitud podrían sesgar el modelo.
La distribución de variables en el dataset original es la siguiente:

Se observa que no existen valores nulos. Existen valores con distintas escalas como trestbps, age, chol, etc., lo que hace necesario el procedimiento de escalado. También eliminaremos la columna id que no tiene ningún significado.
La distribución de las variables del dataset quedaría de la siguiente forma:

Donde hemos aplicado los siguientes técnicas:
- Transformación de datos: hemos normalizados los datos para que todos los datos se distribuya en la misma escala.
- Reducción de la dimensionalidad: hemos eliminado el atributo id que no aporta información al problema.
Construcción del modelo
Una vez realizado el preprocesado de datos podemos empezar con el clustering. Para utilizar el algoritmo k-means necesitamos decidir el número de clústeres por adelantado. También es importante asegurar que los resultados son reproducibles. Por tanto, en cualquier análisis que incorpore algún aspecto aleatorio es importante establecer un valor semilla para el generador de números aleatorios.
En primer lugar, vamos a calcular un modelo con 5 clústeres. Se obtienen los siguientes pacientes:
- Clúster 1: 24 pacientes.
- Clúster 2: 53 pacientes.
- Clúster 3: 87 pacientes.
- Clúster 4: 72 pacientes.
- Clúster 5: 67 pacientes.
Evaluación del modelo
Como se trata de un algoritmo que utiliza una componente aleatoria en la selección de los nodos iniciales diferente iteraciones del mismo crearán diferentes clústeres. Si el algoritmo está agrupando observaciones similares que lo son realmente, las asignaciones al clúster serán robustas entre diferentes ejecuciones del algoritmo. Esto significa, desde el punto de vista de los pacientes con enfermedad cardiovascular, que los mismos pacientes han sido agrupados juntos.
Si los mismos pacientes no están agrupados en el mismo clúster tras diversas iteraciones entonces el modelo no está capturando una relación significativa entre pacientes.
Vamos a realizar una segunda iteración del algoritmo con un modelo de 5 clústeres.
Se obtiene:
- Clúster 1: 51 pacientes.
- Clúster 2: 48 pacientes.
- Clúster 3: 42 pacientes.
- Clúster 4: 67 pacientes.
- Clúster 5: 95 pacientes.
Es muy importante que los clúster resultado del algoritmo sean estables. Si este tipo de algoritmo es la elección apropiada para los datos, diferentes iteraciones del algoritmo generarán clústeres similares. Aunque no sean exactamente iguales sin tendrán aproximadamente el mismo tamaño y distribuciones de variables similares.
Si nos encontramos con muchos cambios en los clústeres para distintas iteraciones entonces el algoritmo k-means no es una buena elección para los datos. Como se trata de una técnica no supervisada no tenemos ninguna etiqueta que nos permita validar los clústeres. No queda otra que estudiar cómo cambian los clústeres entre iteraciones. Vamos a intentar representar visualmente aquellas características que podrían haberse considerado para agrupar a los pacientes juntos. Vamos a representar las variables edad y colesterol para las dos iteraciones:
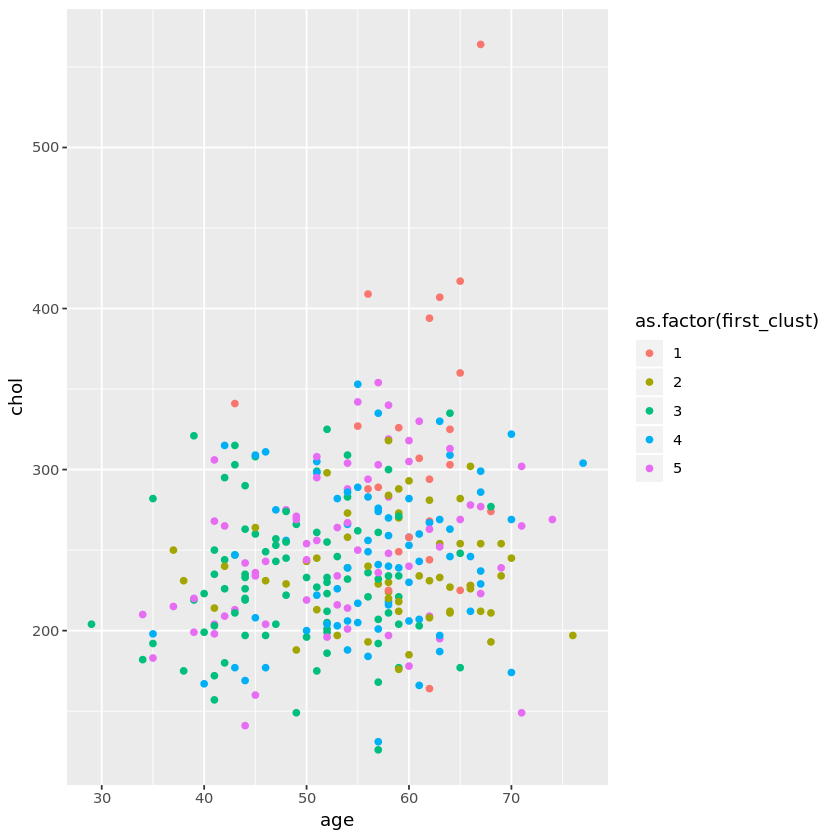
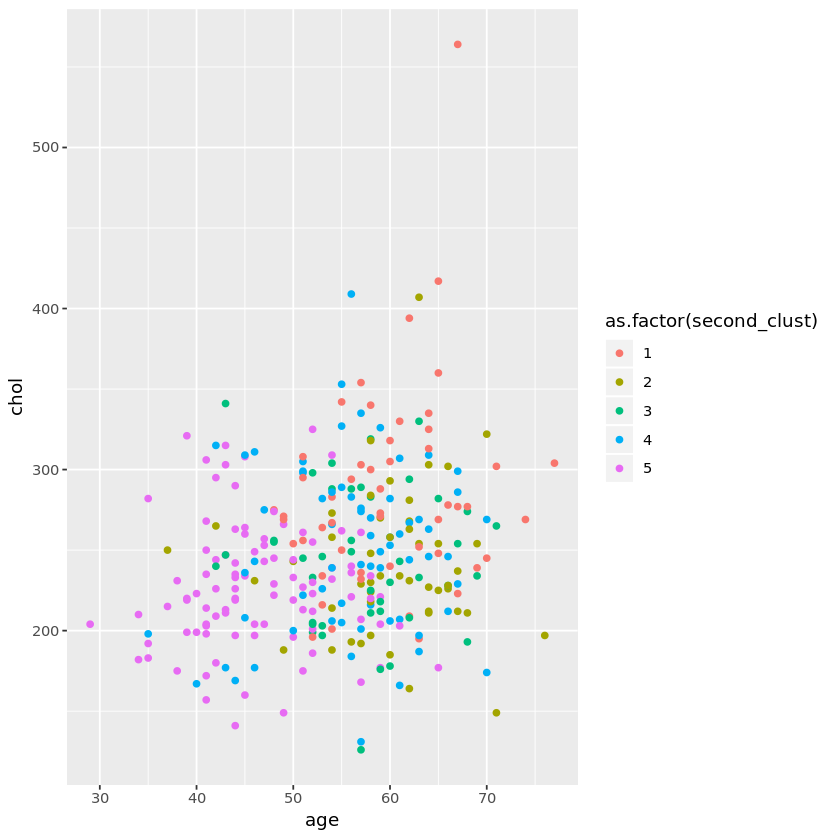
Según observamos hay mucha variabilidad entre los clústeres lo que significa que el algoritmo no es capaz de capturar la estructura subyacente de los datos.
El siguiente paso sería explorar otras posibilidades de agrupamiento como las que nos ofrecen los algoritmos de agrupación jerárquica. Lo veremos en un próximo post.
La idea clave que quisiera que te quedase en mente es que la minería de datos no es una ciencia exacta. Se trata de un proceso descubrimiento y no es un proceso lineal. Es posible que el resultado que obtengamos no permita encontrar la respuesta que buscamos y sea necesario otro intento u otra aproximación al problema.
Espero que te haya resultado ilustrativo este ejemplo de análisis y minería de datos en salud. Este tipo de modelos son los que construimos con nuestra solución Conectando Datos, por lo que si tienes algún tipo de necesidad en este sentido no dudes en contactar conmigo.